Enterprise AI Integration Pattern

Your AI Works.
Nothing Connects
to Anything.
Most enterprise AI fails not because the model is wrong — but because intelligence never reaches the systems where decisions are made. This is an architecture walkthrough of the workflow integration layer that fixes that.
A CDO at a mid-sized financial services firm once showed me their AI programme dashboard. Seven use cases live. Four more in development. Millions invested. Then she said the thing I’ve heard in almost every enterprise AI engagement: “The demos are great. Nobody actually uses them.”
It wasn’t a model problem. The retrieval quality was fine. The answers were accurate. The issue was that every AI output landed in a dead end — a UI nobody opened, a folder nobody checked, a chat interface that existed outside every real workflow the organisation ran.
They had built intelligence in isolation. And isolated intelligence has zero operational value.
This article walks through an architecture pattern I’ve built specifically to solve this problem: an event-driven workflow integration layer that connects document intelligence capabilities to real enterprise systems — triggering on business events, routing outputs to the right channels, and accumulating a persistent knowledge layer as a compounding byproduct.
This is not a RAG tutorial. The vector store and retrieval logic are one component of six. The architecture is the story.
The Architecture: Orchestration First
The platform is structured around a principle that inverts how most GenAI implementations are built: the workflow orchestration layer is the primary architectural concern. Everything else — AI services, vector store, LLM — is subordinate to it.
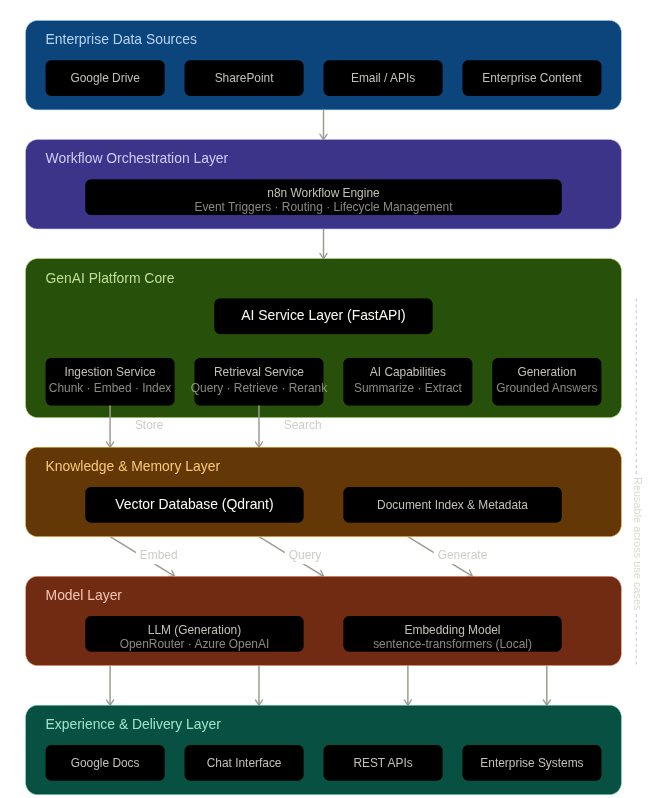
What separates this from a standard GenAI stack is that Layer 2 — orchestration — is not plumbing. It owns what the system does, when, in what sequence, and what happens when things fail. The AI services are powerful but passive. Without the orchestration layer, they do nothing.
What the Orchestration Layer Actually Owns
Most architecture writing glosses over orchestration and spends its words on model selection and retrieval strategies. That’s the wrong emphasis. Here is what the workflow layer is responsible for — and why getting each one wrong breaks the system in production.
Business events — new file in Drive, email with attachment, scheduled batch, API webhook — trigger the workflow automatically. No manual intervention. The AI system responds to what the organisation is already doing.
A single document event fires two simultaneous paths: an analysis path delivering a structured report within minutes, and a knowledge persistence path indexing the document into the queryable knowledge base. Neither waits for the other.
Not every document follows the same path. A contract, a policy document, and a financial report each need different extraction prompts and different output channels. This conditional logic lives in the orchestration layer — not buried inside an AI service.
LLM timeouts. Vector store ingestion failures. Downstream systems unavailable. The orchestration layer owns retry logic, failure escalation, and workflow state — so processing resumes rather than restarts when something goes wrong.
Conditional business logic — which documents go where, what happens on failure, who gets notified — belongs in the orchestration layer. Putting it inside AI services couples concerns that need to evolve independently. When the routing rule changes, you want to change a workflow node, not redeploy an API.
The End-to-End Flow
Here is what happens in this platform when a new vendor contract lands in a monitored Google Drive folder — a concrete trace through all six layers.
EVENT: New file detected in /legal/contracts/ PATH A — Analysis (immediate value) Workflow downloads document → Sends to LLM with structured extraction prompt → Receives: document type, obligations, financial terms, critical dates, risk flags → Formats business-readable report → Writes to Google Docs, notifies stakeholders → Elapsed: ~90 seconds from upload PATH B — Knowledge Persistence (compound value) Workflow sends document text to ingestion service → Semantic chunking + embedding (local model) → Indexed to Qdrant with metadata → Document permanently queryable → Elapsed: concurrent with Path A LATER QUERY: "Total value across all 2024 vendor contracts?" Retrieval service embeds query → Semantic search across entire knowledge base → Grounded generation with source attribution → "Total: $1.24M across 8 agreements [sources cited]"
Two outcomes from one event. The business user gets an immediate deliverable. The organisation accumulates a knowledge base that gets more valuable with every document processed. This compounding dynamic is only possible when the knowledge layer is persistent rather than ephemeral.
AI Services as Reusable Capabilities
The GenAI Platform Core is a set of FastAPI services, each with a single well-defined responsibility. The orchestration layer calls endpoints. It does not care how those endpoints work internally.
This matters because the most common mistake in enterprise AI architecture is coupling AI logic to the workflow that first needed it. A summarisation prompt hardcoded into a workflow node becomes a maintenance liability the moment a second team wants the same capability. Service abstraction means you change it once and every workflow that calls the service benefits.
| Service | Input | Output | Key Decision |
|---|---|---|---|
| Ingestion | Raw document text | Chunks indexed to vector store | Semantic chunking over fixed-size |
| Retrieval | Natural language query | Grounded context only — no answer | Retrieval and generation deliberately separated |
| Capabilities | Document text + prompt config | Structured extraction JSON | Prompt-driven, not hardcoded per doc type |
| Generation | Query + retrieved context | Grounded answer with citations | LLM never touches raw corpus directly |
The deliberate separation of the Retrieval and Generation services deserves emphasis. Keeping them decoupled means you can upgrade the retrieval strategy — add hybrid search, tune reranking, apply metadata filters — without touching the generation logic. These concerns evolve at different rates and for different reasons.
The Reusability Argument
The platform is designed to be configured for use cases, not rebuilt for them. Separating the platform core from the use case layer — event triggers, extraction prompts, output channels — means the same architecture supports fundamentally different operational workflows.
| Use Case | What Changes | What Stays the Same |
|---|---|---|
| Contract Intelligence | Source folder, extraction prompts, Docs output | Platform core ↑ |
| Policy Compliance Q&A | Corpus (SharePoint), chat delivery channel | Platform core ↑ |
| Proposal Generation | Source (past proposals), generation prompt | Platform core ↑ |
| Architecture Knowledge Base | Source (Confluence/GitHub), Slack delivery | Platform core ↑ |
You are not building four systems. You are configuring one platform four times. This is the difference between an AI feature and an AI capability — and it is the only approach that scales across a consulting practice or an enterprise’s multiple business units.
The Compounding Knowledge Layer
The strategic value of this platform is not the document summary it generates today. It is the knowledge base it builds over time.
Six months after deployment, a question like “What are the standard indemnification clauses across all our vendor agreements?” gets answered in seconds — with source citations, across the entire contract history. Without the persistent knowledge layer, that question requires manual review of every contract, every time.
Most AI implementations treat the knowledge extracted from a document as disposable. They ingest, generate, and discard. The architecture described here treats it as a permanent, queryable asset. The platform gets more valuable with every document that flows through it — and that compounding dynamic is the foundation of an enterprise AI capability that organisations keep paying for.
This also positions the platform as agent-ready infrastructure. The persistent knowledge layer and event-driven ingestion pipeline are not just useful for human-facing queries — they are precisely the structured, citable, auditable data plane that AI agents need to reason over enterprise context without hallucinating. An agent tasked with drafting a vendor risk summary does not start from a blank prompt. It starts from a grounded knowledge base that already holds every relevant contract, policy, and prior decision. The architecture described here is the foundation that makes that possible.
The Tech Stack
Workflow Orchestration
AI Platform Core
Knowledge & Model Layer
Enterprise Integrations
Three Trade-offs Worth Naming
An architecture post that only describes what was built is a feature list. The decisions that define a platform are the trade-offs — what you chose not to do, and why.
Local embeddings over API embeddings. At enterprise scale, embedding costs compound quickly. A corpus of 50,000 chunks run through a commercial embeddings API is non-trivial spend — and that cost repeats every time documents are re-indexed. A local sentence-transformers model eliminates per-token embedding cost after the initial download. More importantly for regulated industries: documents never leave your infrastructure during embedding. The trade-off is that you own the compute. For workloads under a million chunks, CPU is adequate. The platform supports both patterns.
Service abstraction over embedded logic. Wrapping each AI capability in a FastAPI service adds a network hop and requires versioning discipline. The payoff is that multiple workflows can call the same service, model changes propagate in one place, and each service can be tested independently. At the scale of a consulting practice or an enterprise platform team, that payoff is significant.
Vendor-neutral model layer over native cloud AI services. The platform uses an OpenRouter-compatible endpoint in development and swaps to Azure OpenAI or AWS Bedrock in production. This adds prompt portability overhead — not every prompt that works on GPT-4o transfers without tuning to another model. The trade-off is that no single vendor holds architectural leverage over the deployment.
What a Production Deployment Requires
This reference implementation demonstrates architectural depth and reusable patterns. It is not a production-hardened deployment. The gap between the two is where most enterprise AI programmes stall — not because the architecture is wrong, but because production introduces a different class of requirements that prototypes do not surface.
In a regulated environment — financial services, insurance, healthcare — the production requirements fall into three categories that cannot be deferred.
Every document processed, every LLM call made, and every output delivered must be traceable. OpenTelemetry instrumentation, immutable audit logs, and an input/output capture layer are non-negotiable for SOC 2, OSFI, and model risk management frameworks.
PII detection before ingestion, content guardrails on generation output, data residency enforcement for documents in scope of PIPEDA or GDPR, and classification-aware routing logic that prevents sensitive documents from reaching unauthorised output channels.
Ground truth evaluation sets, LLM-as-judge scoring for qualitative output quality, automated regression testing when providers update model versions, and human-in-the-loop review gates before AI-generated outputs are acted upon in high-stakes workflows.
Understanding what production requires is itself an architectural signal. Prototypes that acknowledge their gaps are more credible than those that don’t — because it demonstrates that the architect has thought past the demo.
The evaluation, drift detection, and cost governance framework for agentic AI systems in production — including LLM-as-judge scoring, model version pinning, and token budget controls — is covered in detail in the companion piece on the EA Advisor Agent.
EA Advisor: Productionising Agentic AI — Evaluation, Drift & Cost →Why Governance Cannot Be an Add-On
The most common failure mode in enterprise AI is treating governance as a layer you bolt on at the end. The audit trail, the access controls, the output review gates — these get deferred to “after we prove the value.” They are never added. The system goes live without them. Then something goes wrong, and the organisation cannot reconstruct what the AI said, to whom, based on what data.
For a financial services firm operating under OSFI’s model risk management guidelines, or an insurer subject to FSRA oversight, an AI system without a reconstructable decision trail is not a productivity tool. It is a regulatory exposure. The same AI capability that accelerates contract review can create material risk if the output cannot be audited, the model version cannot be identified, or the data lineage from source document to generated answer cannot be traced.
The architecture described in this piece defers those controls as a reference implementation choice — not as a design recommendation. The correct sequence for a regulated enterprise is: governance architecture first, capability layer second. The workflow orchestration layer described here is designed to accommodate governance controls at every decision point — event detection, routing, output delivery, and knowledge persistence — without requiring a re-architecture when those controls are added.
An AI integration platform earns the right to operate in a regulated environment not by being accurate, but by being auditable. Accuracy is necessary but not sufficient. The question a regulator or internal audit function asks is not “did the AI get it right?” — it is “can you show us exactly what it did, why, and what data it used?” Build the answer to that question into the architecture from day one.
Explore the Implementation
Architecture decision records, workflow exports, service APIs, and deployment assets — all on GitHub.